

👋 Hallo, Ed en Chris hier. Het hier en nu is een moment dat eeuwen beslaat. In de Atlas van het Lange Nu schrijven we over diepe historische onderstromen, maatschappelijke denkramen, speculatieve verbeeldingen en onderbouwde toekomstscenario’s.
Vorige maand schreven we over OpenAI’s release van ChatGPT-4, de laatste mijlpaal in de ontwikkeling van kunstmatige intelligentie. We lieten zien hoe deze technologie ons een soort collectieve kunstmatige intuïtie geeft.
Deze laatste versie van ChatGPT heeft sinds haar release het nodig losgemaakt bij de makers en gebruikers van AI. Aan de lopende band verschijnen er nieuwe indrukwekkende toepassingen die duidelijk maken dat de impact van deze technologie enorm is. De impact is zelfs zo groot dat het waarschijnlijk ontwrichtend zal zijn voor de samenleving en we ons moeten afvragen wat de juiste manier is om deze technologie te ontwikkelen en in te zetten. Daarom in deze editie een kleine deep dive waarin we de eerste contouren van het AI landschap in kaart pogen te brengen.
AI take off of pauze
🚀
Om te beginnen een greep uit het recente nieuws om even een gevoel te krijgen over de schaal en impact van deze ontwikkeling:
- ‘ChatGPT + Wolfram can be thought of as the first truly large-scale statistical + symbolic “AI” system’ — ChatGPT kan met de Wolfram-plugin nu ook foutloos wiskundige en natuurwetenschappelijke antwoorden geven, compleet met complexe formules, grafieken en allerlei andere datavisualisaties (Stephen Wolfram).
- ‘It’s institutional memory in a box’ — Bloomberg, de financiële data- en mediagigant, heeft from scratch BloombergGPT gebouwd, waarin het naast publieke data alle data en archieven van het bedrijf heeft gestopt. Daarmee is een domeinspecifieke AI ontstaan die elke financiële analist naar de kroon steekt (Niemanlab).
- ‘We call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4’ — In een open brief van het Future of Life Institute wordt door AI-onderzoekers, -bouwers en -prominenten opgeroepen tot het tijdelijk stoppen van verdere AI-ontwikkeling (Pause Giant AI Experiments: An Open Letter).
- ‘Als je dood wil gaan, doe maar’ — Na zes weken lang in gesprek te zijn geweest met de AI-chatbot-app Chai heeft een Belgische vader van een jong gezin zichzelf van het leven beroofd. De teruggevonden chatgeschiedenis laat de neerslachtige gesprekken en aansporing tot zelfdoding zien. Chai draait op GPT-J en is een kloon van GPT-3, maar met een stuk minder veiligheidsrestricties (De Standaard).
- ‘Italië legt voorlopig het gebruik van de populaire chatbot ChatGPT aan banden’ — De AI van ChatGPT wordt gebouwd met data die van het internet geschraapt is. Volgens Italië schendt dit de privacywetgeving en daarnaast zit er geen beveiliging in ChatGPT die minderjarigen beschermt tegen ongepaste antwoorden van de chatbot. De EU heeft OpenAI een brief gestuurd waarin ze gevraagd wordt binnen drie weken aan te tonen hoe ze aan de Europese privacywetgeving voldoen. Lukt ze dat niet, dan krijgen ze een flinke boete (4% van hun jaaromzet) (NOS).
Deze snelle en turbulente ontwikkeling, en het menselijk leed dat hiermee gepaard gaat, bieden stof tot nadenken. Hoewel de AI-pauzebrief zich ook bedient van enigszins hyperbolisch en angstaanjagend taalgebruik, zoals ‘…powerful digital minds that no one – not even their creators – can understand, predict, or reliably control’, zijn veel van de vragen en voorstellen uit de brief verstandig:
‘AI research and development should be refocused on making today’s powerful, state-of-the-art systems more accurate, safe, interpretable, transparent, robust, aligned, trustworthy, and loyal.
In parallel, AI developers must work with policymakers to dramatically accelerate development of robust AI governance systems. These should at a minimum include: new and capable regulatory authorities dedicated to AI; oversight and tracking of highly capable AI systems and large pools of computational capability; provenance and watermarking systems to help distinguish real from synthetic and to track model leaks; a robust auditing and certification ecosystem; liability for AI-caused harm; robust public funding for technical AI safety research; and well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause.’
Toch heeft de brief iets paradoxaals wanneer je nadenkt over de afzender en de ondertekenaars. Het Future of Life Institute legt zich toe op risico’s die het einde van de mensheid kunnen betekenen, ze noemen dat existentiële risico’s, zoals klimaatverandering, nucleaire wapens, biotechnologie en bovenaan de lijst: kunstmatige intelligentie. Het instituut is dan ook een van de bolwerken waar het gedachtengoed van het longtermism (waar we eerder over schreven) goed vertegenwoordigt is. De ondertekenaars, alsook de mensen in het bestuur, zijn academici en ondernemers uit de techsector. Met andere woorden, het zijn de makers van AI die nu zelf waarschuwen voor de mogelijke gevolgen van hun uitvindingen. Dit voelt enerzijds hypocriet en opportunistisch, en anderzijds als angstaanjagend, want als zij die intiem bekend zijn met de technologie waarschuwen voor haar gevaarlijke impact, dan is het toch goed om te luisteren.
Ook Sam Altman, de CEO van OpenAI, vraagt om regulering van AI-technologie, en zegt dat OpenAI alles zo transparant en publiek mogelijk wil doen, om juist het publieke debat hierover aan te slingeren. Ongeacht eventuele andere motieven is dat in elk geval gelukt.
Voor de regulering van AI-technologie moeten we nadenken over de (minstens) de volgende twee vragen.
- Hoe kunnen we organisaties die AI maken verantwoordelijk houden voor wat ze maken?
- Hoe ziet een verantwoordelijke relatie tussen gebruiker en AI eruit?
Wie is de maker van generatief werk?
💾
Van wie is de data waarmee een AI werkt? Wie is verantwoordelijk voor wat die data, of content, in de wereld teweegbrengt? AI-bedrijven zullen positie moeten gaan kiezen in het licht van bestaande wetgeving.
Op dit moment is de gebruiker verantwoordelijk voor de content die hij of zij publiceert op een platform, maakt met de tools van een platform, of waarnaar het platform verwijst (zoals zoekmachines naar content verwijzen). Dus voor auteursrechtelijke claims en claims over de grenzen van de vrijheid van meningsuiting moet je bij de gebruiker zijn.
Generatieve AI’s zoals ChatGPT en Midjourney hebben onnoemelijk veel materiaal verwerkt waar auteursrecht op zit. Maar wie heeft het auteursrecht op het beeld of het antwoord dat door AI gegenereerd wordt? Er zijn twee mogelijke redenatierichtingen voor het AI-bedrijf.
a) Ze zijn niet verantwoordelijk, want de AI is getraind op content van derden. De makers van die content zijn verantwoordelijk als de chatbot iets zegt wat lijkt op de content. Maar hiermee geven ze toe dat ze materiaal gebruiken waar auteursrecht op ligt, en daar zijn consequenties aan verbonden.
b) AI’s transformeren de oorspronkelijke content dermate dat je niet kan spreken van schending van auteursrechten. De content die AI produceert is originele content. Dit zorgt ervoor dat het auteursrecht bij het AI-bedrijf komt te liggen en dat ze daarmee aansprakelijk zijn wanneer een AI een schadelijke uiting produceert.
Welke kant de generatieve AI-bedrijven op bewegen zal snel duidelijk worden, aangezien er legio rechtszaken zijn gestart waarin deze bedrijven aangeklaagd worden wegens schending van auteursrechten (Getty Images klaagde Stability AI aan, een groep illustratoren klaagden Midjourney, Stable Diffusion en Deviant Art aan voor het gebruik van hun werk, een groep programmeurs klaagden Microsoft, OpenAI en Github aan voor het gebruik van hun code voor de ontwikkeling van Copilot). Het lijkt erop dat auteursrechtenorganisaties werk (grotendeels) geproduceerd met generatieve AI-tools niet zien als werk van diegene die deze AI-tools bedient (zie deze uitspraak van U.S. Copyright Office).
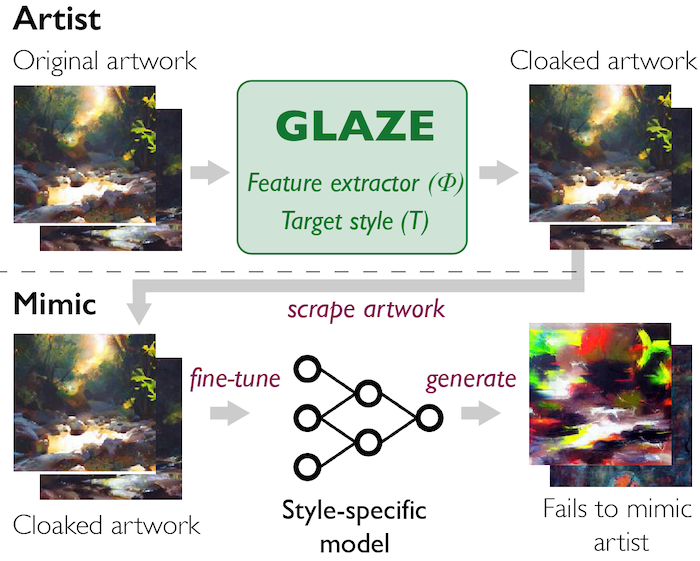
Generatieve AI maakt vragen over waar informatie vandaan komt en hoe feiten onderbouwd worden dus des te urgenter. Wanneer een verschijningsvorm van een tekst, beeld, video of audio ons geen aanknopingspunten meer kan geven over of iets echt of betrouwbaar is, dan is niks meer betrouwbaar en dat is natuurlijk een ramp voor ons publieke domein en de democratische cultuur. Dus uiteindelijk zal, wat ze in de AI-pauzebrief een ‘provenance and watermarking systems to help distinguish real from synthetic’ noemen, nodig zijn. Dat voorstel is trouwens volledig verenigbaar met ons voorstel voor een nieuwe architectuur van vertrouwen, de Universal Data Commons, waarin media wordt voorzien van een bewijsketen van verificaties, certificatie en falsificaties die de oorsprong en bewerkingen van media registreren.
NB: Er zijn nog meer kritische punten over hoe AI-bedrijven te werk gaan, een groep kritische AI-onderzoekers zette ze op een rijtje in deze open brief in reactie op de AI-pauzebrief.
Hoe werk je samen met een generatieve ‘collega’?
🤖
ChatGPT en andere AI-chatbot’s zijn een heel ander type gereedschap dan we tot voor kort kenden. Ons gebruik van computers, maar ook allerlei oudere technologie, maakte van ons gebruikers, bestuurders en beoefenaars van gereedschappen en instrumenten. Als gebruikers zaten wij aan de knopen, wij gaven de commando’s en moesten de ‘taal’ van een specifiek soort gereedschap leren om iets te kunnen maken met dat gereedschap. Of het nu om een fotocamera, een tekstverwerker of een muziekinstrument gaat, voor alle geldt: oefening baart kunst. Hoe moeilijker en complexer het instrumentarium, hoe steiler de leercurve.
ChatGPT daarentegen heeft onze taal geleerd, en we kunnen er mee in gesprek gaan zonder dat we fundamenteel nieuwe vaardigheden hoeven te leren. Dit levert echter een soort verwarring op, want onze omgang met machines was altijd gereedschap-achtig. Sam Altman zegt dat veel mensen GPT als een database, een soort feitenmachine à la Google, benaderen, maar dat is niet wat het is. Het is een redeneermachine.
ChatGPT vertelt je inderdaad soms onwaarheden, halve waarheden, verzint niet-bestaande bronnen en praat je naar de mond. Maar het kan zichzelf ook corrigeren. Wanneer je het een opdracht geeft en een fout in het antwoord vindt, en je vervolgens aan GPT vraagt of het de opdracht correct heeft uitgevoerd, is het in staat de eigen fout te herkennen en te corrigeren.
Het is dus niet alsof GPT een feitje uit een database ophaalt, of dat het harde logica beoefent, het is eerder vergelijkbaar met hoe we zelf redeneren. We hebben een gedachte, die we uitspreken of opschrijven, we reflecteren erop, hebben een vervolggedachte en/of corrigeren een vorige gedachte, krijgen een nieuwe associatie of een nieuw inzicht, etc. Al denkende, schrijvende of pratende wordt het verhaal of het argument duidelijker en helderder. Let wel, met redeneren bedoel ik hier dus eerder een informele vorm van het reflecteren op en het toetsten van onze intuïties, en niet de formele logica van de wiskunde of filosofie.
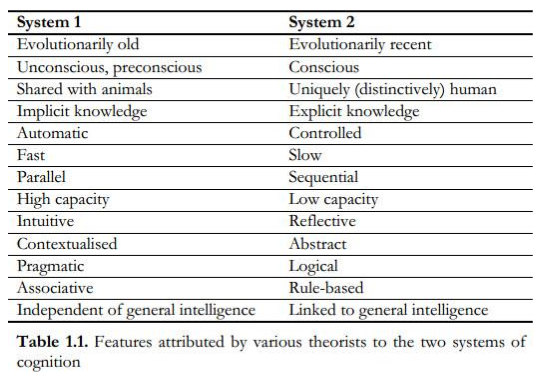
The brain moves forward using intuition. Reasoning is the intuition we use to discover an explanation of our intuitions.‘
Als je samen met GPT dus gedachtes, argumentaties, projecten of opdrachten verkent, kan het een waardevolle gesprekspartner zijn, en al helemaal wanneer GPT toegang heeft tot bergen verifieerbare data, programmeertalen, de exact-wetenschappelijke zoekmachine van Wolfram, andere AI-tools en allerhande software.
Computerwetenschappers hebben met het bovenstaande als uitgangspunt nu automatische systemen gebouwd waarin ChatGPT zichzelf ondervraagt of waarin het kan reflecteren op de opdrachten die het krijgt, waardoor het betere antwoorden gaat geven. Met deze zelfreflectie-methode kan GPT dus een betere versie van zichzelf zijn zonder dat er een nieuw model getraind hoeft te worden.

Een chatbot kan dus een waardevolle collega, persoonlijke assistent, mentor, docent, adviseur, coach of therapeut zijn. En daar zit ook het grootste gevaar volgens de criticasters: we vermenselijken het gereedschap. We dichten een machine menselijke kwaliteiten toe, zoals bewustzijn, empathie, verantwoordelijkheidsgevoel, vermogen tot lijden en een eigen gedachtewereld. Een chatbot die je naar de mond praat, je dieper een depressie intrekt en beaamt dat het oké is om jezelf van het leven te beroven is extreem gevaarlijk. Het is belangrijk te weten dat er geen intentie, empathie of begrip achter berichten zit, maar enkel een enorm statistisch taalmodel. Wanneer wij als mensen worden aangesproken in onze eigen taal, zijn we nog niet gewend dat de woorden die gesproken of geschreven worden het product zijn van zeer complexe maar gedachteloze statistiek.
Enerzijds moeten wij als gebruikers dus leren dat AI chatbotmachines zijn zonder bewustzijn, anderzijds moeten de AI’s zo worden vormgegeven dat wij eraan herinnerd worden dat het geen levende wezens zijn. Dus misschien mag een AI in de toekomst niet meer spreken met termen als ‘ik denk’ of ‘ik voel’ en mag het zich niet meer voordoen als een menselijke avatar. Daarnaast moeten AI-chatbots zich verantwoord gedragen. Dit wordt ook wel het alignment-probleem genoemd: de AI moet zich binnen gedefinieerde kaders bewegen en de wettelijke vangrails, maatschappelijke normen en waarden (die per cultuur weer anders zullen zijn), maar ook de vertrouwensrelatie tussen de AI en zijn gesprekspartner respecteren.
ChatGPT-4 doet het wat dat betreft redelijk goed. Het is genuanceerd, belicht meerdere kanten van argumenten en helpt gebruikers niet met bommen maken, Jodenhaat en zelfmoordpogingen. Zorgelijker zijn de minder transparante AI’s die virtuele AI-vriendschap aanbieden aan een groep die psychologisch kwetsbaar is.
Een pas op de plaats en goede spelregels voor AI lijken ons een goed idee, al moeten we ons daarbij niet laten leiden door apocalyptische angstprojecties van een soort Terminator-toekomst, maar eerder focussen op hoe de AI-race onderweg geen slachtoffers maakt, een misinformatiemachine wordt, of macht concentreert bij een handje vol techbedrijven.
Veel liefs, Christiaan en Edwin ❤️


{kind=link}